



Note: This post about Speech Emotion Recognition covers only the basics of practical implementation of DNN for an emotion classification problem. In order to dive deeper, contact Vivoka.
Motivation behind Speech Emotion Recognition
Have you ever called a phone service? How was your experience? It is usually very frustrating when you have a robot asking you a bunch of questions. Now imagine you are upset, you decide to call back the company, and still get a robot on the other end of the line. That is an example in which you could try to recognize speech emotion with machine learning and improve customer services. Adding emotions to machines has been recognized as a critical factor in making machines appear and act in a human-like manner [1].
Speech Emotion Recognition (SER) is the task of recognizing the emotion from speech irrespective of the semantic contents. However, emotions are subjective and even for humans it is hard to notate them in natural speech communication regardless of the meaning. The ability to automatically conduct it is a very difficult task and still an ongoing subject of research.
This post aims to help you to build an emotion recognizer from speech data using a deep neural network. It includes light explanations and descriptions of what you can use for your first experiments.
RAVDESS Dataset
We use a freely available dataset called Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) that contains both audio (speech and song) and video data. We will only use the audio (speech) files made by 24 actors (12 male and 12 female) vocalizing two lexically-matched statements in a North American accent. Speech includes eight expressed emotions (neutral, calm, happy, sad, angry, fearful, disgust and surprise) expressed in normal and strong intensity. The image below shows the count of utterances for each emotion.
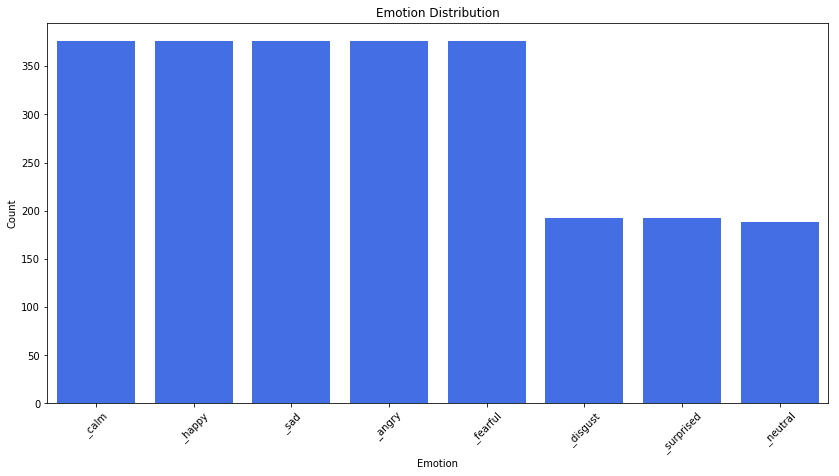
We will try to classify all the different emotions available in the dataset with a light approach that you can use as a baseline. This post aims at three emotions among those eight. Vivoka provides a multilingual SER engine that deals with the eight emotions with high accuracy.
Before making our neural network first we need to collect useful features from each audio file.
Speech Preprocessing
Turn Sounds into Numbers
Sound is vibrations that propagate as an acoustic wave. The first step in working with audio files is to turn the audio wave into numbers so that you can feed this into your machine learning algorithm. You can think of sound as waves that move over time and can be plotted as seen below:

You can measure the height of this wave at equal intervals. This is exactly what the sampling rate means. You are basically doing thousands of samples every second. Each point represents the amplitude of your audio file at the instant t and will be turned into an array of numbers.
Note: The Nyquist Shannon theorem establishes the rule that sampling rate should be at least two times the highest frequency component of the audio to capture the right components and build your samples. The habitual hearing frequency range of a healthy young person is from 20 to 20,000Hz [2].
Feature Extraction
We are going to collect five different features from each audio and fuse them in a vector.
- Melspectrogram: Compute a Mel-scaled power spectrogram
- MFCC: Mel-frequency cepstral coefficients. The shape of the vocal tract manifests itself in the envelope of the short time power spectrum, and the job of MFCCs is to accurately represent this envelope. More details in [3]
- Chorma-stft: Compute a chromagram from a waveform or power spectrogram
- Spectral_contrast: Compute spectral contrast, using method defined in [4]
- Tonnetz: Computes the tonal centroid features (tonnetz), following the method of [5]
If you do not know about all these, no need to worry. The Python package Librosa will do all the work for you.

So each audio file will have a fixed vector size of 193. The functions used for this purpose are taken from [6]. Keep in mind that getting to this point took me some time. It is very important that you understand how to use the librosa library to extract audio features as this will definitely impact the results of your model.
Default Model
Architecture
Our deep neural network consists of:
- One input layer
- One hidden layers
- Drop out
- One hidden layers
- Drop out
- One hidden layer
- Drop out
- One output layer.
This architecture was randomly chosen (you should try a different one). Dropout rate is used to prevent overfitting during the training phase. If you do not know how to define a DNN then keras documentation can help you.
Hyperparameters
- Hidden_units for the first hidden layers: approximately twice the input dimension
- Hidden_units for the second hidden layers : half of the first layer
- Hidden_units for the second hidden layers : half of the second layer
- Optimizer: Adam
- Dropout rate: 20%
- Activation function: relu
- Loss function :‘categorical_crossentropy’,
- Epochs: 200
- Batch size: 4
Here, you can take 70% of the data training and the remaining 30% for testing. The training will take some time.
Results and Discussion about Speech Emotion Recognition
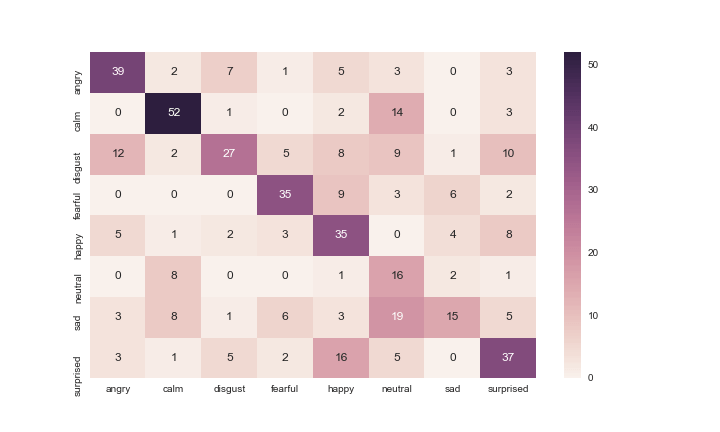
Well, it seems that this classifier is showing moderate performance.
There are many that you can do to improve the accuracy of this model.
- Try to extract some other features from the audios and experiment with them.
- Tweak the architecture of the DNN (try out different numbers of layers, optimizer, number of epochs etc)
- Apply other types of neural networks like CNN, RNN etc.
Major Obstacles
- It is hard to define the notion of emotions because they are subjective, and even people would interpret it differently. It is hard to define the notion of emotions.
- Annotating an audio recording is challenging. Should we label the whole conversation, a single part, which one(s)? How many emotions should we define to recognize?
- Collecting data is complex. There are several audio datasets that can be achieved from films or news. However, both of them are biased since news reporting has to be neutral and actors’ emotions are imitated. It is hard to look for neutral audio recording without any bias.
- Labeling data requires high human and time cost. It requires trained personnel to analyze it and give an annotation. The annotation result has to be evaluated by multiple individuals due to its subjectivity.
Keep in Mind
- You should define the emotions that are suitable for your own speech recognition project.
- Exploratory Data Analysis always grants us good insight. You have to be patient when you work on audio data.
- Deciding the input for your model: a sentence, a recording or an utterance?
- Lack of data is a crucial factor to achieve success in SER, however, it is complex and very expensive to build a good speech emotion dataset.
- Simplified your model when you lack data.