



Note : Cet article sur la reconnaissance vocale des émotions ne couvre que les bases de la mise en œuvre pratique de la DNN pour un problème de classification des émotions. Pour approfondir le sujet, contactez Vivoka.
Les motivations derrière la reconnaissance vocale des émotions
Avez-vous déjà appelé un service téléphonique ? Comment s’est déroulée votre expérience ? Il est généralement très frustrant d’avoir un robot qui vous pose un tas de questions. Imaginez maintenant que vous soyez contrarié, que vous décidiez de rappeler la société, et que vous ayez quand même un robot à l’autre bout du fil. C’est un exemple dans lequel vous pourriez essayer de reconnaître l’émotion à travers la parole avec l’apprentissage automatique et améliorer le service à la clientèle. L’ajout d’émotions aux machines a été reconnu comme un facteur essentiel pour faire apparaître et agir les machines de manière humaine [1].
La reconnaissance vocale des émotions est le processus pour reconnaître l’émotion d’un discours indépendamment de son contenu sémantique. Cependant, les émotions sont subjectives et même pour les humains, il est difficile de les noter dans la communication vocale naturelle, quel qu’en soit le sens. La capacité à la réaliser automatiquement est une tâche très difficile et fait toujours l’objet de recherches.
Cet article a pour but de vous aider à construire un outil de reconnaissance vocale des émotions à partir de données vocales en utilisant un réseau neuronal profond. Il comprend des explications et des descriptions légères de ce que vous pouvez utiliser pour vos premières expériences.
Ensemble de données RAVDESS
Nous utilisons un ensemble de données en accès libre appelé Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) qui contient à la fois des données audio (parole et chant) et vidéo. Nous n’utiliserons que les fichiers audio (parole) de 24 acteurs (12 hommes et 12 femmes) qui vocalisent deux énoncés lexicaux assortis avec un accent nord-américain. La parole comprend huit émotions exprimées (neutre, calme, heureux, triste, fâché, craintif, dégoût et surprise) exprimées avec une intensité normale et forte. L’image ci-dessous montre le nombre de paroles pour chaque émotion.
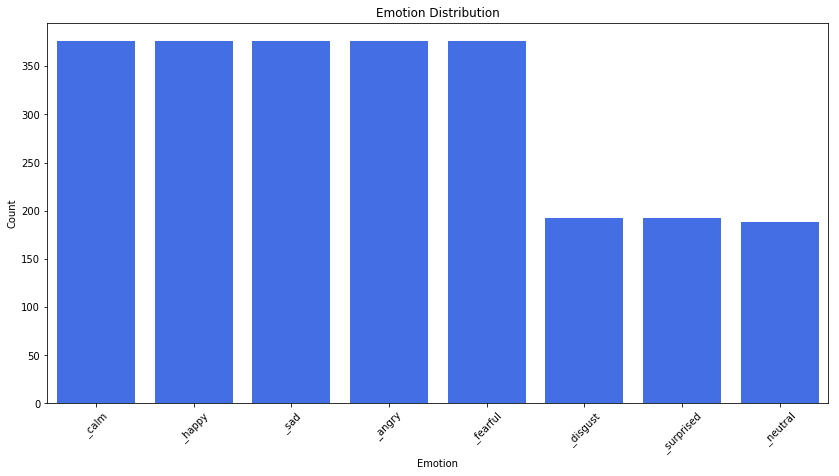
Nous allons essayer de classer toutes les différentes émotions disponibles dans l’ensemble de données avec une approche légère que vous pouvez utiliser comme fondation. Ce poste vise trois émotions parmi ces huit. Vivoka fournit un moteur SER multilingue qui traite les huit émotions avec précision.
Prétraitement de la parole
Transformer les sons en chiffres
Le son est une vibration qui se propage comme une onde acoustique. La première étape pour travailler avec des fichiers audio consiste à transformer l’onde audio en nombres afin de pouvoir les intégrer dans votre algorithme d’apprentissage machine. Vous pouvez considérer le son comme des ondes qui se déplacent dans le temps et qui peuvent être tracées comme indiqué ci-dessous :

Vous pouvez mesurer la hauteur de cette vague à intervalles réguliers. C’est exactement ce que signifie le taux d’échantillonnage. Vous faites en fait des milliers d’échantillons chaque seconde. Chaque point représente l’amplitude de votre fichier audio à l’instant t et sera transformé en un tableau de nombres.
Note: Le Nyquist Shannon theorem établit la règle selon laquelle le taux d’échantillonnage doit être au moins deux fois supérieur à la composante de fréquence la plus élevée de l’audio pour capturer les bonnes composantes et construire vos échantillons. La plage de fréquences d’audition habituelle d’une jeune personne en bonne santé est de 20 à 20 000 Hz [2].
Extraction des caractéristiques
Nous allons collecter cinq caractéristiques différentes de chaque audio et les fusionner dans un vecteur.
- Melspectrogram : Calculer un spectrogramme de puissance à l’échelle de Mel
- MFCC : Coefficients cepstraux de fréquence mel. La forme du conduit vocal se manifeste dans l’enveloppe du spectre de puissance à court terme, et le travail des MFCC consiste à représenter précisément cette enveloppe. Plus de détails dans cette [3].
- Chorma-stft : Calculer un chromagramme à partir d’un spectrogramme de forme d’onde ou de puissance
- Contraste_spectral : Calculer le contraste spectral, en utilisant la méthode définie dans [4]
- Tonnetz : Calcule les caractéristiques du centroïde tonal (tonnetz), selon la méthode [5]
Si vous ne savez pas tout cela, ne vous inquiétez pas. Le paquet Python Librosa fera tout le travail pour vous.

Ainsi, chaque fichier audio aura une taille vectorielle fixe de 193. Les fonctions utilisées à cet effet sont tirées de [6]. Gardez à l’esprit qu’il m’a fallu un certain temps pour en arriver là. Il est très important que vous compreniez comment utiliser la bibliothèque librosa pour extraire des caractéristiques audio car cela aura certainement un impact sur les résultats de votre modèle.
Modèle par défaut
Architecture
Notre réseau neuronal est composé de :
- One input layer
- One hidden layers
- Drop out
- One hidden layers
- Drop out
- One hidden layer
- Drop out
- One output layer.
Cette architecture a été choisie au hasard (vous devriez en essayer une autre). Le Dropout rate est utilisé pour éviter le suréquipement pendant la phase de formation. Si vous ne savez pas comment définir un DNN, la documentation de Keras peut vous aider.
Hyperparamètres
- Hidden_units pour les premières couches cachées : environ deux fois la dimension d’entrée
- Hidden_units pour les deuxièmes couches cachées : la moitié de la première couche
- Hidden_units pour les secondes couches cachées : la moitié de la seconde couche
- Optimizer: Adam
- Dropout rate: 20%
- Activation function: relu
- Loss function :‘categorical_crossentropy’,
- Epochs: 200
- Batch size: 4
Ici, vous pouvez prendre 70% des données pour l’entraînement et les 30% restants pour les tests. La formation prendra un certain temps.
Résultats et discussions à propos de la reconnaissance vocale des émotions
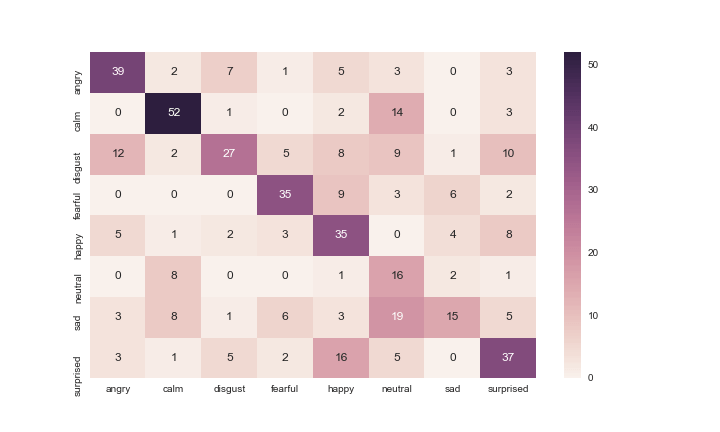
Eh bien, il semble que ce classificateur affiche des performances modérées.
Il y a beaucoup de choses que vous pouvez faire pour améliorer la précision de ce modèle.
- Essayez d’extraire d’autres caractéristiques des audios et expérimentez-les.
- Ajustez l’architecture du DNN (essayez différents nombres de couches, optimiseurs, nombres d’époques, etc.)
- Appliquer d’autres types de réseaux neuronaux comme CNN, RNN etc.
Obstacles majeures
- Il est difficile de définir la notion des émotions car elles sont subjectives, même les individus les interpréteraient différemment. Il est difficile de définir la notion d’émotions.
- Annoter un enregistrement audio est un défi. Faut-il étiqueter la conversation entière, une seule partie, la ou lesquelles ? Combien d’émotions devrions-nous définir pour les reconnaître ?
- La collecte de données est complexe. Il y a beaucoup d’ensembles de données audio qui peuvent être obtenues à partir de films ou de nouvelles. Cependant, les deux sont biaisées car les reportages d’actualité doivent être neutres et les émotions des acteurs sont imitées. Il est difficile de rechercher un enregistrement audio neutre sans aucun biais.
- L’étiquetage des données nécessite un coût humain et temporel élevé. Il faut un personnel formé pour l’analyser et y apporter une annotation. Le résultat de l’annotation doit être évalué par plusieurs personnes en raison de sa subjectivité.
Points clés
- Vous devez définir les émotions qui conviennent à l’objectif de votre propre projet.
- L’analyse exploratoire des données nous donne toujours un bon aperçu, et il faut être patient quand on travaille sur des données audio !
- Décider de l’entrée pour votre modèle : une phrase, un enregistrement ou un énoncé ?
- Le manque de données est un facteur crucial pour la réussite de l’analyse exploratoire des données, mais il est complexe et très coûteux de construire un bon ensemble de données sur les émotions de la parole.
- Simplifiez votre modèle lorsque vous manquez de données.