




Derrière la reconnaissance automatique de la parole se cache le moyen de communication humaine le plus courant : la parole. Elle est définie comme l’expression de pensées et de sentiments par l’articulation de sons. Naturellement, nous pouvons communiquer beaucoup plus avec notre voix qu’avec un texte. Une personne moyenne peut écrire environ 50 mots par minute, alors qu’elle peut en dire beaucoup plus : environ 150.
Cependant, notre communication ne se résume pas à compter le nombre de mots par minute que nous parlons. Dans le discours, le contexte (séquence de mots), le public, l’humeur de l’orateur et plusieurs autres facteurs sont importants. C’est pourquoi le discours est complexe et compliqué. La communication humaine est impensable sans la parole.
En parlant, nous activons trois processus principaux : la synthèse de la parole, la reconnaissance vocale et la compréhension de la parole.
Comment les humains communiquent-ils ?
Depuis les années 1950, les logiciels de reconnaissance vocale ont fait du chemin. En particulier, avec la submersion des approches d’apprentissage profond depuis la dernière décennie, les chercheurs ont fait des progrès significatifs sur ce problème et un grand bond en avant a été réalisé dans ce domaine. Récemment, des machines ont commencé à reconnaître notre parole et à améliorer nos capacités de communication. En effet, les assistants vocaux actuels, comme Alexa et Google Home, deviennent de plus en plus populaires chaque mois. Ces appareils changent beaucoup de choses, en particulier la manière dont nous interagissons avec les machines, la façon dont nous faisons nos courses, etc.
L’objectif principal d’un système de reconnaissance vocale automatique (ASR) est de « simuler » l’auditeur humain qui peut « comprendre » une langue parlée et « répondre ». Cela signifie que la reconnaissance automatique de la parole doit tout d’abord convertir la parole en un autre support tel que le texte.
La parole nous permet de transformer nos pensées en un son qui exprime une langue. En général, la communication par la parole passe par plusieurs processus complexes :
- Formuler des idées en mots.
- Générer des sons en utilisant les cordes vocales (et le système de parole).
- Transmettre le son par une onde acoustique (sous forme de vibrations dans l’air) à l’oreille de l’auditeur.
- Transmettre les vibrations au cerveau de l’auditeur par l’intermédiaire des nerfs auditifs.
- Convertit ces vibrations en séquences de mots dans son cerveau.
- Extraire le sens des mots.
(Une vidéo amusante pour montrer la complexité de la parole – Source: Fastest talker – Guinness World Records)
Pourquoi la reconnaissance automatique de la parole est difficile pour les machines ?
Pour l’instant, la reconnaissance automatique de la parole peut être considéré comme une boîte noire construite à partir d’un logiciel et d’un matériel (tel qu’un microphone). Il prend comme entrée la voix (speech) et renvoie la transcription des mots prononcés dans le discours. Nous détaillerons cette boîte dans les prochains blogs.

Les humains font de la reconnaissance vocale presque sans effort. Cependant, pour les machines, la reconnaissance vocale est difficile car l’écoute est complexe et plus compliquée qu’on ne le pense. Voyons comment fonctionne le processus humain et ce qu’une machine devrait faire :
- Les humains ont naturellement l’anatomie dédiée pour accepter une onde acoustique, tandis que les machines devraient convertir le signal analogique (l’onde acoustique) en représentation numérique.
- Lorsque quelqu’un nous parle (dans une salle de classe par exemple), nous devons alors séparer ses mots (son signal acoustique) de tout le bruit de fond. En général, le bruit peut être le discours du professeur, les conversations d’autres personnes, la circulation (oui, cela peut arriver même dans la salle de classe), etc. Par conséquent, la machine doit séparer la parole du bruit.
- Certaines personnes parlent lentement, tandis que d’autres parlent vite. D’autres ne s’arrêtent pas, ou ne ralentissent pas à la fin de la phrase avant d’en commencer une nouvelle. Dans ce cas, les phrases sonnent comme un long flux continu de mots (et ne peuvent donc pas distinguer les phrases). En outre, il est ambigu lorsqu’un mot se termine et qu’un autre commence. Dans ce cas, une machine devrait traiter ces séparateurs dans la parole.
- De nombreux facteurs tels que le sexe, l’âge, l’accent, le contexte, l’humeur influencent notre voix. C’est pourquoi chacun sonne différemment. Même si vous demandez à quelqu’un de dire deux fois « Quelle heure est-il ? », il ne le dira probablement pas de la même manière à chaque fois, simplement parce que les voix changent très souvent. Ici, la machine doit résister à la variabilité de la parole.
- Plus encore, supposons que nous soyons dans une conversation avec un enfant, une femme adulte, un vieil homme et plusieurs autres personnes, qui ont tous des accents différents. Nous devons alors donner un sens à l’ensemble du fil de la conversation et à ce que chacun dit. Nous devons comprendre que le mot « porte », par exemple, signifie la même chose, peu importe qui le dit. Ainsi, la machine devra reconnaître les sons même s’ils sont prononcés différemment « dog » ou « doooooor » par des personnes radicalement différentes, américaines, anglaises, espagnoles…
- Il y a beaucoup de mots qui ont un son similaire (c’est-à-dire homophones) ou identique (comme « to », « too », « two ») mais leur signification est différente. Ici, le contexte est nécessaire afin de savoir quelle signification l’orateur entend. Dans ce cas, une machine doit désambiguïser les homophones.
- Il existe de nombreux « fillers » que nous utilisons dans la parole, tels que « um », « hmm », « euh » etc. et nous savons instinctivement comment les filtrer. et nous savons instinctivement comment les filtrer.
- Ils ne nous trompent pas ou ne nous amènent pas à interpréter incorrectement les paroles de l’orateur. La machine devrait également filtrer ces remplissages.
- Parfois, nous entendons mal les phrases, donc nous les comprenons mal. Comme de telles erreurs pourraient être très gênantes, la machine devrait également gérer ces malentendus, et doit être nettement meilleure que nous dans cette tâche.
- Enfin, si tout cela ne semble pas beaucoup, nous devons connaître la syntaxe et la sémantique de la langue que nous utilisons ainsi que le contexte.
Il est étonnant que nous fassions tout cela dans une simple conversation. En ce sens, nos cerveaux sont incroyables. Il n’est donc pas étonnant que les machines luttent pour faire tout cela. Pourtant, la reconnaissance vocale a fait beaucoup de chemin, et ce n’est peut-être que le début.
Les différentes composantes de la reconnaissance automatique de la parole
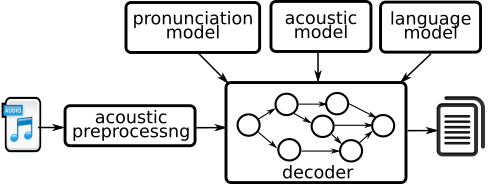
Un système de reconnaissance automatique de la parole est généralement composé des éléments suivants :
- Représentation numérique pour l’entrée (et une méthode pour l’extraire)
- Composant d’extraction de caractéristiques : Elle identifie les parties de l’entrée contenant de la parole et transforme ensuite ces parties en séquences de ce que l’on appelle des paramètres acoustiques.
- Données / corpus pour la formation et les tests : Cette base de données est une collection de discours enregistrés, enrichie des annotations et transcriptions requises. Ce corpus doit être suffisamment important et pertinent pour couvrir la variabilité de la parole dans un cas d’utilisation donné.
- Modèles acoustiques : Un modèle acoustique prend la forme d’onde de la parole et la décompose en petits fragments et prédit les phonèmes les plus probables de la parole.
- Modèles de prononciation : Un modèle de prononciation prend les sons et les relie entre eux pour former des mots, c’est-à-dire qu’il associe les mots à leurs représentations phonétiques.
- Modèles de langage : Un modèle de langue prend les mots et les relie entre eux pour former des phrases, c’est-à-dire qu’il prédit la séquence de mots (ou de chaînes de texte) la plus probable parmi plusieurs ensembles de chaînes de texte.
- Algorithmes permettant de rechercher efficacement l’espace d’hypothèse (appelés décodeurs) : Il combine les prédictions des modèles acoustiques et linguistiques et produit la chaîne de texte la plus probable pour une entrée de fichier vocal donnée.
Le but du système est de combiner ces différents modèles pour obtenir une estimation de la probabilité d’une séquence sonore déjà observée (dans la base de données vocales) étant donné la phrase d’entrée. Le système effectue ensuite une recherche dans l’espace de toutes les phrases, et choisit la phrase ayant la plus grande probabilité d’être la phrase source d’entrée. Ce mécanisme est appelé inférence.
Maintenant, pensez à l’ensemble de toutes les phrases françaises – cet ensemble est incroyablement massif, nous avons donc besoin d’un algorithme efficace qui ne cherche pas dans toutes les phrases possibles, mais seulement dans les phrases qui ont une chance suffisante de correspondre à l’entrée, ce qui fait qu’il s’agit d’un problème de recherche (également appelé problème de décodage).
Pour conclure sur la complexité de la reconnaissance automatique de la parole
Dans cet article, nous avons abordé certaines des difficultés de la reconnaissance vocale, qui est une tâche très complexe, mais pas insurmontablement difficile. Récemment, les ASR ont obtenu de très bons résultats qui ont conduit les machines à améliorer leur « traitement auditif », mais l’approche optimale dépend de la compréhension de la transcription des ASR. Pour transformer réellement la parole en mots, ce n’est pas aussi simple que de cartographier des sons discrets, il faut aussi comprendre le contexte. Idéalement, le logiciel devrait encoder une expérience humaine de toute une vie.
Quelques références (anciennes mais pertinentes)
- Gold, B., Morgan, N., & Ellis, D. (2011). Speech and audio signal processing: processing and perception of speech and music. John Wiley & Sons.
- Shneiderman, B. (2000). The limits of speech recognition. Communications of the ACM, 43(9), 63-65.
- Teller, V. (2000). Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition. Computational Linguistics, 26(4), 638-641.





