




Présentation des technologies d’ASR embarqué
Les assistants vocaux tels que Siri, Alexa, Google Assistant, ont tous pour but d’aider le client à parler aux ordinateurs le plus naturellement possible grâce à l’ASR embarqué (Automatic Speech Recognition) et au traitement/compréhension du langage naturel (TAL/NLU). Aujourd’hui, il y a un besoin émergent pour des ASR à faibles ressources qui sont robustes, précis et qui peuvent être déployés dans des dispositifs embarqués comme les smartphones ou les Raspberry Pi.
Ce blog donne un aperçu de quelques-uns des ASR les plus référencés pour les dispositifs embarqués : DeepSpeech, Wav2Letter, PocketSphinx, Pico Voice. Nous ne faisons pas de classement, mais présentons ces solutions en fonction de leurs développeurs, de leurs approches et des résultats obtenus.
ASR Embarqué : Quelles sont les solutions disponibles ?
DeepSpeech par Mozilla

DeepSpeech est un moteur de transcription vocale open-source, qui utilise un modèle formé par des techniques d’apprentissage automatique et basé sur le papier de recherche Baidu’s Deep Speech. DeepSpeech utilise TensorFlow de Google, le tout sous licence MPL-2.0..
Mozilla a publié DeepSpeech avec des modèles pour l’anglais américain qui sont plus petits et plus rapides, ainsi qu’un modèle TensorFlow Lite pour les appareils embarqués. Cet ASR est composé de deux sous-systèmes principaux :
- Modèle acoustique : un réseau neuronal profond qui reçoit des caractéristiques audio en entrée et produit des probabilités de caractères. Le modèle acoustique a été entraîné sur l’anglais américain et atteint un taux d’erreur de 5,97% sur le corpus de test LibriSpeech.
- Décodeur : Utilise un algorithme de recherche de faisceau CTC pour transformer les probabilités de caractères en transcriptions textuelles qui sont ensuite renvoyées par le système.
Notez que le modèle acoustique donne de meilleurs résultats dans des environnements peu bruyants avec des enregistrements clairs et qu’il a un biais vers les accents masculins américains. Cela ne signifie pas que le modèle ne peut pas être utilisé en dehors de ces conditions, mais que la précision peut être moindre. Certains utilisateurs peuvent avoir besoin d’entraîner davantage le modèle pour répondre à leur cas d’utilisation prévu. La latence est rapide sur un seul cœur d’un Raspberry Pi 4.
Wav2Letter par Facebook

Wav2Letter est un système de reconnaissance vocale sous licence BSD qui a été développé par Facebook AI research sur la base d’une approche End to End et en utilisant MFCC, spectre de puissance ou ondes brutes comme entrée. Le modèle acoustique combiné au décodage graphique produit directement la transcription sans qu’il soit nécessaire de forcer l’alignement des phonèmes. L’évaluation introduit une métrique appelée LER (Letter Error Rate).
Les résultats en termes de WER/LER sont compétitifs avec l’état de l’art sur Librispeech avec un LER de 6.9 et un WER de 7.2 avec MFCC comme entrées. L’approche est donc plus performante en termes de coût de calcul et a une procédure d’entraînement moins fastidieuse que les approches HMM/GMM. Récemment, Wav2Letter a évolué vers une boîte à outils orientée vers la performance, permettant de choisir parmi différentes architectures de réseau, fonctions de perte et entrées.
PocketSphinx par CMUSphinx’s

PocketSphinx est conçu pour les modèles légers, d’où le préfixe « pocket ». Il fait partie d’une plus grande boîte à outils orientée vers la recherche et les ressources de CMUSphinx, publié sous une licence de type BSD. PocketSphinx est basé sur une approche classique avec un modèle de langue statistique, un modèle acoustique HMM et un dictionnaire mot à phonème. Les modèles sont construits à partir des bases de données LDC et CMU_ARCTIC. Benchmark cités par PicoVoice (cf. sous-section suivante) montrent que le WER de ce modèle est de 31,82% en utilisant le modèle de base english us.
Module ASR embarqué par Picovoice

Développée par la société canadienne Picovoice. Cette solution est construite grâce à une plateforme cloud utilisée pour entraîner les modèles, et un SDK multi-langue open source pour les exécuter. Parmi leurs produits, ils ont deux ASR embarqués : Leopard et Cheetah.
La principale différence est que Cheetah permet d’obtenir des résultats partiels (résultats pendant l’analyse) alors que Leopard ne le permet pas. Leopard et Cheetah ne sont disponibles qu’en anglais (Picovoice a récemment commencé à développer ses projets dans d’autres langues européennes). Ces ASRs sont fournis pour un usage personnel et non commercial uniquement.
L’architecture de ces ASR n’a pas encore été révélée. Néanmoins, ils semblent avoir une approche classique, combinant un modèle acoustique et un modèle de langage, en utilisant l’apprentissage automatique propriétaire comme architecture. Leur benchmark montre dans le tableau 1 qu’ils ont construit un modèle de langage spécifique au corpus de formation (librispeech) pour obtenir de meilleurs résultats :
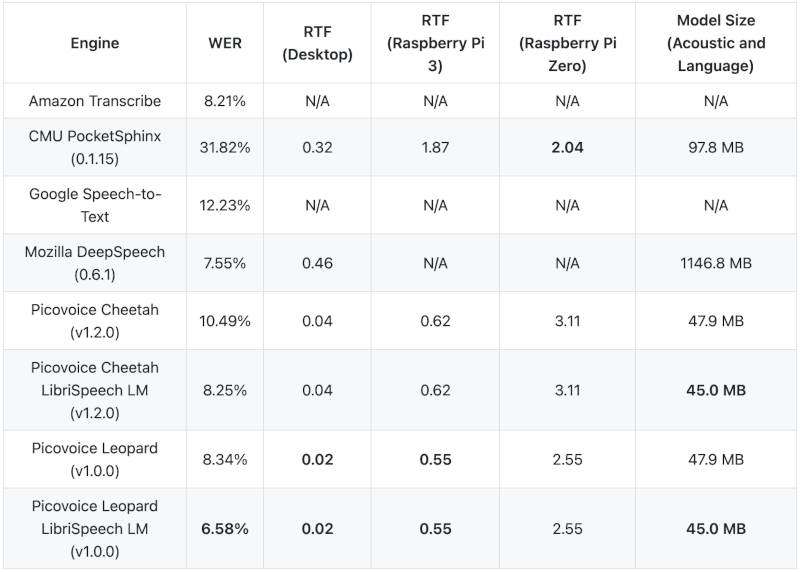
Table 1. Benchmark provided by Picovoice
Quels sont les éléments à prendre en compte pour un ASR embarqué?
En général, la performance des ASR dépend des données de formation qui sont souvent conditionnées. Cela crée un écart entre les performances théoriques et pratiques des ASR. Cela peut s’expliquer par le fait que les modèles qui dépendent de dix mille heures de données ne sont pas très intéressants parce que, la plupart du temps, construire autant de données du bon type est un grand défi. Dans ce cas, l’apprentissage par transfert peut être adopté comme une solution pour affiner les ASR pré-entraînés avec des données et des performances raisonnables.





