




Introducing Offline ASR Technologies
Voice Assistants like Siri, Alexa, Google Assistant, all aim to help the customer to talk to computers as naturally as possible through offline ASR (Automated Speech Recognition) and Natural Language Processing/Understanding (NLP/NLU). Today, there is an emerging need for low-resources ASRs that are robust, accurate and that can be deployed in embedded devices like smart-phones or Raspberry Pi.
This blog provides an overview of some of the most referenced ASRs for embedded devices: DeepSpeech, Wav2Letter, PocketSphinx, Pico Voice. This offline ASR comparison does not give a ranking, but rather present these solutions according to their developers, approaches and the obtained results.
Offline ASR: What solutions are available?
Mozilla’s DeepSpeech

DeepSpeech is an open source Speech-To-Text engine, using a model trained by machine learning techniques and based on Baidu’s Deep Speech research paper. DeepSpeech uses Google’s TensorFlow, all under the MPL-2.0 license.
Mozilla released DeepSpeech along with models for US English that have smaller and faster models and have a TensorFlow Lite model for embedded devices. This ASR is composed of two main subsystems:
- Acoustic model: A deep neural network that receives audio features as inputs, and outputs character probabilities. The acoustic model was trained on American English and achieves an 5.97% Word Error Rate (WER) on the LibriSpeech clean test corpus.
- Decoder: Uses a CTC beam search algorithm to transform the character probabilities into textual transcripts that are then returned by the system.
Note that the acoustic model performs best in low-noise environments with clear recordings and has a bias towards US male accents. This does not mean the model cannot be used outside of these conditions, but that accuracy may be lower. Some users may need to train the model further to meet their intended use-case. Latency is fast on a single core of a Raspberry Pi 4.
Facebook’s Wav2Letter

Wav2Letter is a BSD licensed Speech Recognition System that was developed by Facebook AI research on the basis of an End to End approach and using MFCC, power spectrum or raw waves as input. The acoustic model combined with graph decoding directly output the transcription without the need for force alignment of phonemes. The evaluation introduces a metric called LER for Letter Error Rate.
Results in terms of WER/LER are competitive with state of the art on Librispeech with a LER of 6.9 and a WER of 7.2 with MFCC as inputs. The approach therefore performs more in terms of computation cost and has a less fastidious training procedure than HMM/GMM approaches. Recently, Wav2Letter has evolved into a performance oriented toolkit, allowing to choose amongst different network architectures, loss functions and inputs.
CMUSphinx’s PocketSphinx

PocketSphinx is designed for lightweight models, hence the “pocket” prefix. It is a part of a bigger research oriented toolkit and resources from CMUSphinx, released under BSD style license. PocketSphinx is based on a classical approach with a statistical language model, an HMM acoustic model and a word to phoneme dictionary. Models are built from LDC and CMU_ARCTIC databases. Benchmark cited by Pico Voice (cf. next subsection) show this model’s WER at 31.82% using the base english us model.
Picovoice’s own ASR technology

Developed by the canadian company Picovoice. This solution is built thanks to a cloud platform used to train models, and an open source multi language SDK to run them. Amongst their products they have two embedded ASR: Leopard and Cheetah.
The main difference is that Cheetah enables partial results (results while parsing) while leopard does not. Leopard and Cheetah are only available in english (recently Picovoice started to develop their projects in other european languages). These ASRs are provided for personal & non-commercial use only.
The architecture behind these ASRs is still not revealed. Nonetheless, they seem to have a classic approach, combining an acoustic model and a language model, using proprietary machine learning as architecture. Their benchmark shows in the table 1 that they built a language model specific to the training corpus (librispeech) for better results:
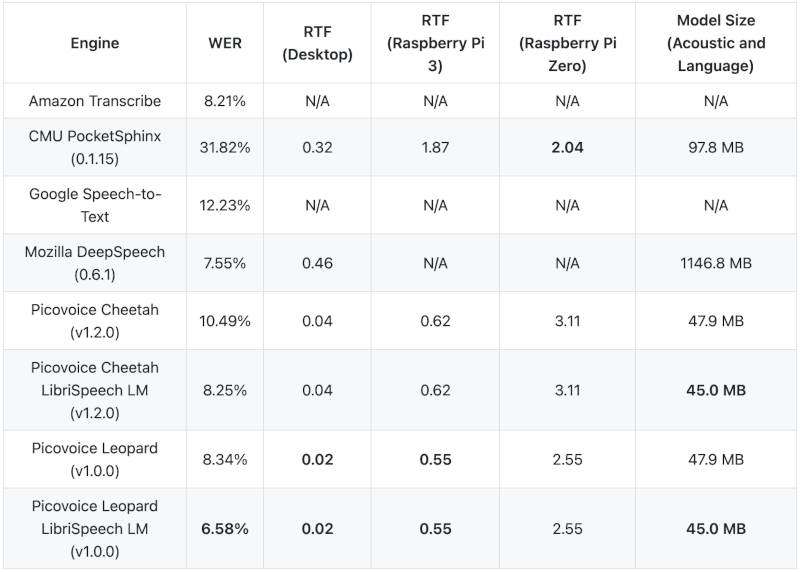
Table 1. Benchmark provided by Picovoice
What elements should you keep in mind from Offline ASR?
Usually, the performance of ASRs depends on the training data that is often conditioned. This creates a gap between theoretical and practice performances of ASR. This can be explained by the fact that models that depend on ten thousand hours of data are not that interesting because most of the time building that much data of the right type is a big challenge. In this case, Transfer Learning can be a solution to finetune pretrained ASRs with reasonable data and reasonable performance.
Vivoka’s technology
ASR is the cornerstone of any voice interaction. In order to build the best possible voice user experience, you need to make sure yours is robust and accurate enough for your use case, whether it is offline or not. Vivoka provides a powerful ASR solution inside the VDK that you can complement with other technologies such as:
- NLU,
- voice synthesis
- audio enhancement…
Contact us and start building your own offline speech recognition system!





