




Behind an ASR resided the most common means of human communication: speech. It is defined as the expression of thoughts and feelings by articulating sounds. Naturally, we can communicate much more with our voices than through text. An average person can write about 50 words per minute, while he can say much more: about 150.
However, our communication is not just a count of how many words per minute we speak. In speech, the context (sequence of words), the audience, the mood of the speaker and several other factors matter. That is why speech is complex and complicated. Human communication is unthinkable without speech.
While speaking, we activate three main processes: speech synthesis, speech recognition, and speech understanding.
How do humans communicate?
Since the 1950s, automatic speech recognition (ASR) software has come a long way. Especially, with the submersion of the Deep Learning approaches since the last decade, researchers have made significant progress on this problem and a great leap in this field has been reached. Recently, machines started to recognize our speech and improve better communication skills. Indeed, current voice assistants like, Alexa and Google Home are getting more and more popular each month. These devices are changing many things, in particular the manner we interact with machines, how we do shopping, etc.
The main goal of an automatic speech recognition system (ASR) is to “simulate” the human listener that can “understand” a spoken language and “respond”. This means the ASR must first of all convert the speech into another medium such as text.
Speech allows us to transform our thoughts to a sound that expresses a language. Usually, speech communication go through several complex processes:
- Formulate ideas into words.
- Generate sound using the vocal cords (and speech system).
- Transmit the sound via an acoustic wave (as vibrations in the air) to the ear of the listener.
- Transmit the vibrations to the listener’s brain via auditory nerves.
- Convert those vibrations to some sequences of words in his brain.
- Extract the meaning from the words.
(A funny video to show the complexity of the speech – Source: Fastest talker – Guinness World Records)
Why is it hard for machines to do ASR?
For now, an ASR can be seen as a black box built from a software (called speech recognizer) and hardware (such as microphone). It takes as input the voice (speech) and returns the transcription of the spoken words in the speech. We will detail that box in later blogs.

Humans do speech recognition almost effortlessly. However, for machines speech recognition is hard because listening is complex and more complicated than we may think. Let’s see at how the human process works and what a machine would need to do:
- Humans naturally have the dedicated anatomy to accept an acoustic wave, while machines would have to convert the analog signal (the acoustic wave) into digital representation.
- When someone speaks to us (in a classroom for example), then we have to separate his words (his acoustic signal) from all the background noise. Generally, noise can be the teacher’s speech, other people’s conversations, traffic (yes, it may happen even in the classroom), etc. Therefore, the machine would have to separate the speech from noise.
- Some people speak slow, whereas others speak fast. Some others do not make stops, or do not slow down at the end of the sentence before starting a new one. In this case, the sentences sound like a continuous long stream of words (so can not distinguish sentences). In addition, it is ambiguous when one word ends and another begins. Here, a machine would need to deal with these separators in speech.
- Many factors such as gender, age, accent, context, mood influence our voices. That is why everyone sounds different. Even if you ask someone to say twice “What time is it?”, he would probably not say it in the same way each time, simply because voices change very often. Here, the machine should resist the variability in speech.
- Even more, suppose we are in a conversation with a child, an adult woman, an old man, and several other people, all of them have different accents. Then, we have to make sense of the whole conversation thread and what everyone is saying. We have to figure out that the word “door” for example means the same thing no matter who says it. Thus, the machine would have to recognize sounds even if they’re said differently “dog” or “doooooor” by drastically different people, American, English, Spanish…
- There are many words that sound similar (i.e homophones) or identical (like “to”, “too”,“two”) but their mean is different. Here, the context is needed in order to know which meaning the speaker intends. In this case, a machine has to disambiguate homophones.
- There are many fillers we use in speech, such as “um”, “hmm”, “euh” (in French) etc., and we instinctively know how to filter them. These don’t throw us off-track or they don’t lead us to interpret the speaker’s words incorrectly. The machine would also have to filter these fillers.
- Sometimes, we can hear sentences incorrectly, so misunderstand them. Because such errors in could be very annoying, the machine would also have to manage such misunderstandings, and needs to be significantly better than us at this task.
- Finally, if all that doesn’t sound like a lot, we have to know the syntax and semantics of the language we’re using as well as the context.
It is astonishing that we do all this in a simple conversation. In this sense, our brains are incredible. It is not surprising, then, that machines struggle to do all of this. Still, speech recognition has come a long way, and this might be just the beginning.
The different components of Automatic Speech Recognition
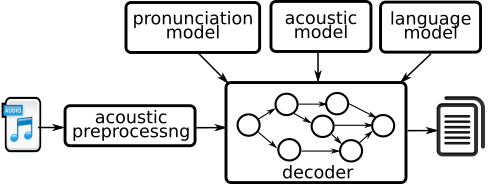
An ASR System is typically composed of the following components:
- Digital representation for input (and a method of extracting it)
- Feature extraction component: This identifies parts of the input containing speech and then transforms those parts into sequences of what is known as acoustic parameters.
- Data / corpus for training and testing: This database is a collection of recorded speech enhanced with required annotations and transcriptions. This corpus has to be large enough and relevant enough to cover the variability of speech in a given use case.
- Acoustic models: An acoustic model takes the waveform of speech and breaks it up into small fragments and predicts the most likely phonemes in the speech.
- Pronunciation models: A pronunciation model takes sounds and ties them together to make words, i.e. it associates words with their phonetic representations.
- Language models: A language model takes the words and ties them together to make sentences, i.e. it predicts the most likely sequence of words (or text strings) among several sets of text strings.
- Algorithms to search the hypothesis space efficiently (known as a decoder): This combines the predictions of acoustic and language models and outputs the most likely text string for a given speech file input.
The goal of the system is to combine these different models to get an estimate for the probability of an already-observed-sound-sequence (in the speech database) given the input sentence. The system then searches through the space of all sentences, and chooses a sentence with the highest probability of being the input source sentence. This mechanism is called inference.
Now, think about the set of all English sentences — this set is incredibly massive, so we need an efficient algorithm that does not search through all possible sentences, but only searches through the sentences that have a good enough chance of matching the input, thus making this is a search problem (also called the decoding problem).
To conclude with ASR complexity
In this article we have addressed some of the difficulties of speech recognition, which is a very complex task, but not unsolvably hard. Recently, ASRs achieved very good results that led machines to improve their “auditory processing”, but the optimal approach depends on the understanding of ASR transcription. To actually turn speech into words, it’s not as simple as mapping discrete sounds, there has to be an understanding of the context as well. The software would ideally need to have a lifetime of human experience encoded in it.
Some (old but pertinent) references
- Gold, B., Morgan, N., & Ellis, D. (2011). Speech and audio signal processing: processing and perception of speech and music. John Wiley & Sons.
- Shneiderman, B. (2000). The limits of speech recognition. Communications of the ACM, 43(9), 63-65.
- Teller, V. (2000). Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition. Computational Linguistics, 26(4), 638-641.





