

The field of voice technologies is continuously growing. While there was a brief decrease in the interest for it these past few years, today there is no doubt that voice is experiencing a resurgence. Major advances in hardware and technology, along with a rise in voice-enabled interfaces, are fueling innovative use cases. In many instances, it’s not only about voice commands, but additional voice technologies such as this blog’s subject: Speaker Recognition.
Speaker Recognition: What do we know about it?
According to Dr. Sadaoki Furui’s definition, “Speaker Recognition is the process of automatically recognizing who is speaking by using the speaker-specific information included in speech waves to verify identities being claimed by people accessing systems; that is, it enables access control of various services by voice”. Fundamentally, we use it to answer the question “Who is speaking?”. The following scheme synthetizes typical way Speaker Recognition works: 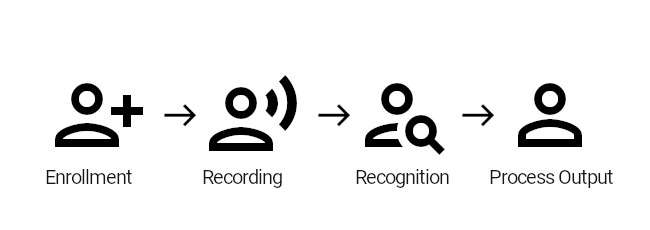 As of today, there are two major reasons for using Speaker Recognition softwares: identification and verification.
As of today, there are two major reasons for using Speaker Recognition softwares: identification and verification.
- Speaker Identification focuses on determining the origin of a given utterance between different enrolled (or registered) speakers;
- In contrast, Speaker Verification works to accept or reject the identity a speaker claims.
Technically, it is the number of possible alternatives that really separates identification from verification. In the case of speaker identification, there are as many alternatives as there are people registered. Whereas for Speaker Verification, it is a 1:1 matching process and there are only two decisions: acceptance or rejection…If you want some additional information, go check our article about voice biometrics!
Speaker Recognition as we know it: mostly IVRs in Call Centers
Historically, Speaker Recognition debuted in the late 90’s with some experiments. In fact, between 1996 and 1998, this technology was used at the Scobey–Coronach Border (between the USA and Canada). Indeed, the goal was to enable enrolled local residents, who had nothing to declare, to cross the border when the inspection stations were closed for the night. Since then, we can see traces of Speaker Recognition technologies in a lot of fields and applications. In a large majority of cases, it revolves around Call Centers to enable verification of a claimed customer identity during a conversation with a live agent or IVR interaction (Interactive Voice Response). The technology certainly isn’t new. In 2013, Barclays was among the first adopters of a passive, “free speech”, voice verification system for authenticating private banking clients. Speaker recognition system allows them verifying a customer’s identity within just 30 seconds of normal conversion and greatly improves security.
A growing trend for in many sectors
The incorporation of speaker recognition technology into various industries exemplifies its broad utility and the continuous improvement of voice processing systems. For instance, in the realm of customer support, this technology can swiftly verify a user’s identity by comparing their voice features against a stored voice model, thereby streamlining the verification process and improving the user experience. Additionally, in educational tools and language learning applications, speaker recognition helps personalize the learning experience by adapting to the unique pronunciation and speaking patterns of each user.
In security-sensitive environments, such as banking or access control systems, speaker recognition acts as a critical layer of defense, using voice data to confirm the identity of individuals before granting access or processing transactions. This application not only enhances security but also adds a layer of convenience for users, eliminating the need for physical tokens or passwords.
Moreover, the integration of open-source technologies and solutions with proprietary systems allows for a more collaborative approach in refining speech recognition models. By harnessing the power of vast datasets and state-of-the-art training techniques, these systems continuously learn and adapt, pushing the boundaries of what automated voice-based systems can achieve in terms of accuracy and reliability.
Now let’s get more into detail for each and every use case:
- Financial Services in Call Centers or Banking Institutions where most of the use cases are centered around Caller Verification for specific operations. For instance, in 2016, HSBC decided to add voice biometrics as a secondary authentication factor. Indeed, after an online cyber attack, the company decided to improve its security system with speaker recognition.
Voice recognition technology is crucial for robust verification processes in fields such as healthcare (medical appointments, access to diagnosis information…)and legal, where secure access to sensitive personal databases is essential.
- Healthcare in multiple areas, from healthcare to legal etc… Fields that deal with personal database access that needs robust verification techniques.
- Retail and Infomercial was and still is a place where Speaker Recognition is used to identify a user and verify their identity to do certain operations like purchasing an item.
- Hospitality such as Hotels, Medical Appointments… for identifying someone that could be present in the client database and verify their identity regarding sensitive operations that involve payment or privacy.
Challenges impacted the accuracy of early voice biometric products. Indeed, robustness in noisy environments, poor telephony connections, the compression of audio in the contact center, and the ability to efficiently isolate speakers made the adoption difficult. The technology was often met with resistance by business leaders. Indeed, they believed it lacked the necessary security and/or performance to efficiently authenticate users. This is now changing. AI made advancements and innovations possible AI and these are breaking down technological barriers to voice biometric adoption. Whereas, rising fraud drives contact centers to replace weak, inefficient authentication methods. For instance, today speaker recognition technology is even able to recognise synthesised or recorded voices. Thus, it limit cases of deepvoices. These factors are resulting in new advantages and opportunities for using voice biometrics in contact centers… and elsewhere.
What to expect from the future of Speaker Recognition technologies.
Contact Centers still use the features related to Speaker Recognition systems through phone channels. Nowadays, use cases are driven by upcoming consumer environments and devices that focus on innovative experiences and secured interactions. Indeed, with IoT booming, smart equipment is everywhere and capable of many things. By that we mean being able to understand and answer the user with voice. Smart homes, cars and cities are closer than we think. And for speaker recognition, this is a new playground to expand in.
Speaker and Speech Recognition to build tailored user experiences
Shifting from telephone channels to smart devices, embedded or not. This is what to expect from the future of speaker recognition. Recognizing a speaker by their voice makes it possible to fully customize any voice experience. With more voice-enabled devices making their way into our daily routines, this ability is undeniably important for companies which strive for better customer satisfaction and engagement. Smart Speakers for instance would be able to recognize who is speaking and adapt their behaviours and answers depending on the person. If a child tries to make a payment through a voice-enabled service, it would reject it since the child wouldn’t have the required authorization. Moreover, a whole new world of experiences could be addressed when different people are using the same product or service. Indeed, we could imagine a specific workflow for each of them, tailor it around preferences and behavioural information. And what’s even better is that devices do not require to be connected. It is possible to embed speaker recognition technology anywhere thanks to major advances in model size and overall technology footprint. Our partner IDR&D recently joined our Voice Development Kit to introduce on-device voice biometrics to our set of technologies. Coupled with our embedded ASRs, our customers can now meet this kind of tailored use cases where a speaker can be recognized when voice-interacting with any device.
Added layer of security in customer journey
While user experience is mostly related to user identification, we often associate security with speaker verification. This side of voice biometrics also has a tumultuous past due to the lack of trust businesses were having for this technology, regarding tasks with potential risks. But, for the same reason that phone channels found a way to be efficient, today’s speaker recognition technologies can meet enterprise-grade requirements. Then it would be considered as a reliable authentication method. With businesses wanting to increase security and at the same time enhancing their products or services workflows by granting frictionless customer journeys, speaker verification is building its path as one of the most expected solutions. To reinforce authentication, companies want to find new methods and tools, but also combine different solutions (2FA with mobile or third party apps like Authenticator). Speaker verification is, in this sense, perfectly adapted to merge with other authentication processes. It can compensate for their limitations as well as granting intuitive and robust voice-print authentication in physician or digital access use cases for instance.
As these technologies evolve, they pave the way for more innovative applications, such as real-time multilingual communication and enhanced human-computer interaction, where the seamless recognition of spoken commands and interactions becomes pivotal. This ongoing advancement in speaker recognition demonstrates its vital role in shaping future interactions between technology and humans, fundamentally altering how we connect with and through machines.
Continued advancements in speaker recognition technology also play a pivotal role in the realm of smart home devices and virtual assistants, where voice commands are central to user interactions. These systems rely heavily on robust models that can discern commands over background noise and execute actions with high precision. The integration of noise reduction algorithms and real-time processing enhances the system’s ability to understand and react to human speech, making technology more intuitive and responsive to human needs.
Overall, the diverse applications of speaker recognition technology across various sectors underscore its transformative potential. By continuously enhancing the performance, accuracy, and adaptability of these systems through deeper neural networks and more sophisticated learning algorithms, we are pushing the boundaries of how machines understand and interact with human speech, creating more personalized, secure, and efficient environments.





