



We don’t present it anymore, you read it in the title, we’re going to talk about voice assistants and big data. This massive turning point in the decade is surely what has most affected the way companies, especially in IT, have rethought their entire strategy. This trend, led by the biggest technological players, has placed data at the center of attention, already because we are today capable of generating and processing an enormous amount of it, but also because it lays the foundations for self-learning artificial intelligence (cf. Machine Learning). This emergence, in addition to overturning most markets, has reshaped the economy, in terms of R&D, Business Models or even the profiles sought after in companies, by placing data at its center.
Now that this little introduction has been made, let’s get to the heart of the matter, does data have any importance on our technologies, such as voice assistants for example?
What is the relationship between data and voice assistants?
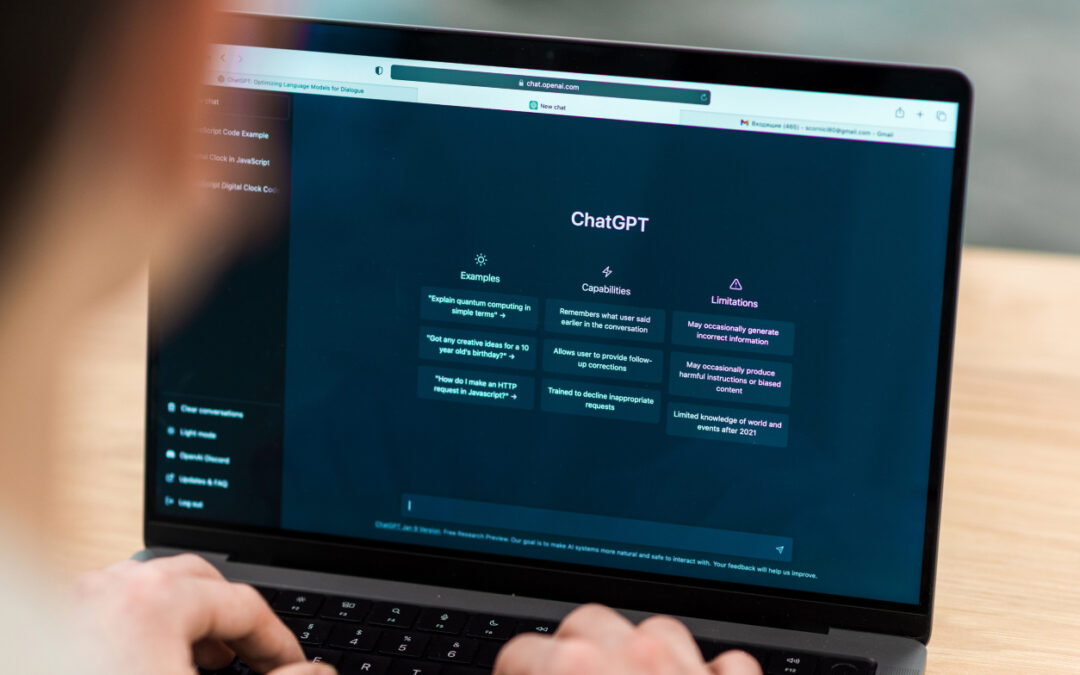
Let’s go back to the origin, what is a voice assistant in fact? It is an artificial intelligence equipped with different technologies related to the field of voice (STT, NLP, TTS to name a few, we advise you to read our article on speech recognition to better understand). Having this nature of AI (artificial intelligence), voice assistants are therefore totally linked to Big Data because the models on which they are designed depend a lot on them.
To be more precise, the majority of wizards you know or use today are developed through machine learning technologies (Machine Learning, Deep Learning etc…) which are algorithms capable of processing information to derive knowledge. Thus, to have an intelligent system, capable of understanding and adapting to many situations, it is strongly recommended to administer a maximum of data to it.
Why is data important for voice technologies?
It’s a bit the same principle as for us humans, data is assimilated to knowledge, so providing qualitative data to a model capable of processing them is like providing a good teaching. In this case, both Man and Machine become efficient because the knowledge base on which they are based is exhaustive and precise. Conversely, you will have understood that there are gaps.
Since their appearance in the 2010’s, voice assistants have been competing for comprehension rates. Sometimes 95%, sometimes 95.3%, it’s a question of going further each time to achieve the best percentage. To accomplish this, you’ll surely guess, it’s a matter of having high-performance models, an optimal suite of technologies, all powered by what? Data.
The problem being that for very generalist solutions like those of GAFAM, it is difficult to have data capable of covering all user profiles. Thus, artificial intelligence technologies, which not only require large amounts of information, incorporate this data from voice recordings that correspond to the majority of individuals. As a result, people with strong accents or those who have difficulty expressing themselves cannot use these firms’ voice assistants.
Are all voice assistants affected by that?
This represents the separation visible today in the world of voice assistants. On the one hand, there are ultra-generic assistants, ambitious to respond to the slightest request and therefore highly dependent on data, as exhaustive as possible. On the other hand, there are dedicated voice assistants, adapted to particular contexts and environments, which in this case only need a small field of data, very relative to their use. For example, a voice assistant in the hotel industry will need to know the hotel jargon and vocabulary associated with the environment in priority. Depending on the use case, the lexical rigor will be different and therefore the data requirement will vary.
Like other technologies that are becoming more widely available today, voice assistants are still dependent on data because the models they are based on require it. Thus, both the quantity and quality of data are important and above all correlated: the ideal is to have as much rich data as possible. Fortunately for our assistants, the data race is not yet over. To really persist in our daily lives, voice solutions need to evolve, and this will necessarily involve training artificial intelligence.